Once upon a time eth0 was eth0 on Linux. But then, some people thought it would be a good idea to rename the network interface on boot to correspond and map the name to the physical interface. In many cases, that is a good idea, but for virtual machines that suddenly and miraculously change the physical interface when the bare metal server config is changed, this approach is a bit of a pain. Recently, however, I noticed that if the network is configured via netplan you can get eth0 back!
Continue reading Netplan and How To Get eth0 Back!Netcup – Part 3: Smooth Packet Jitter
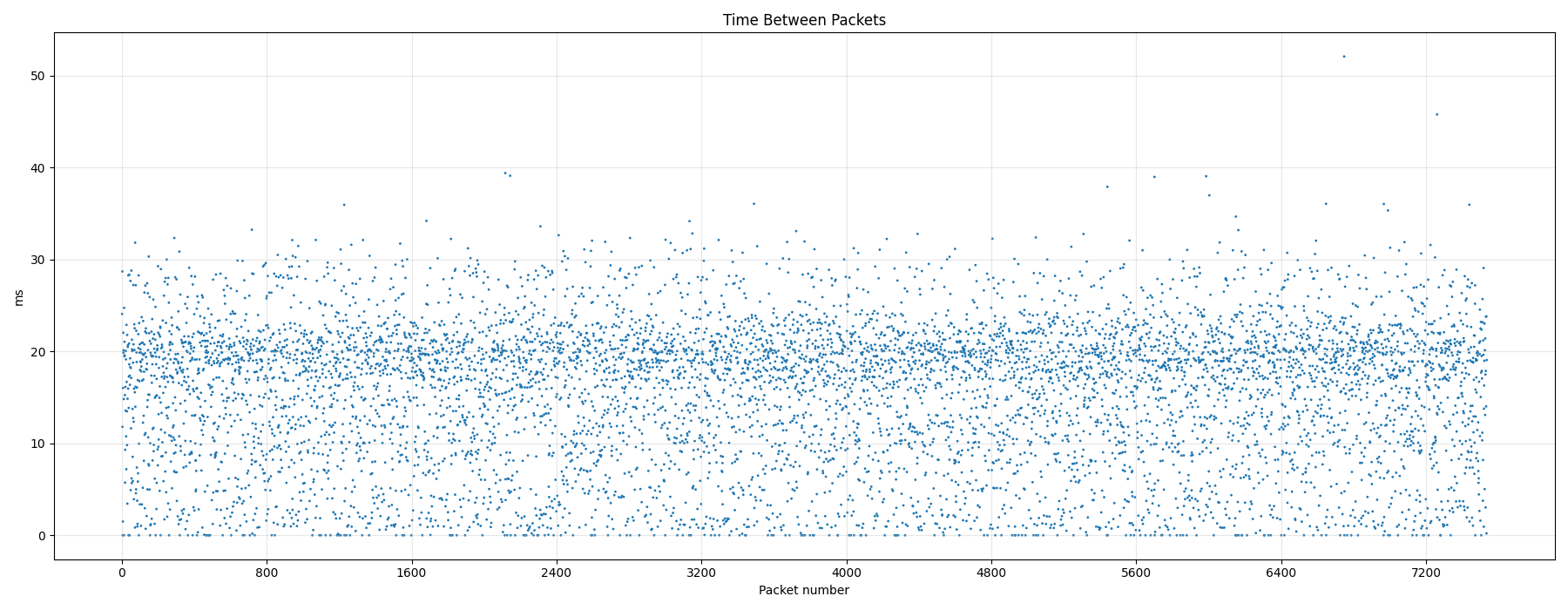
In part 1 of this series I’ve used this blog as a quick test of Netcup’s tiny and cheap VM offer that I have come quite fond of in the meantime. So it was time to move a ‘real’ application to it I was running on a more expensive VM in a different data center: My TURN server for which I have quite stringent packet jitter requirements.
Continue reading Netcup – Part 3: Smooth Packet JitterNetcup – Part 2: Up/Downloading Disk Images
In the previous post I described my first experiences with Netcup and that the server management interface held a pleasant surprise I would describe in a follow up post. So here it is: Uploading and downloading disk images!
Continue reading Netcup – Part 2: Up/Downloading Disk ImagesNetcup – Part 1: Tiny VMs For Cheap
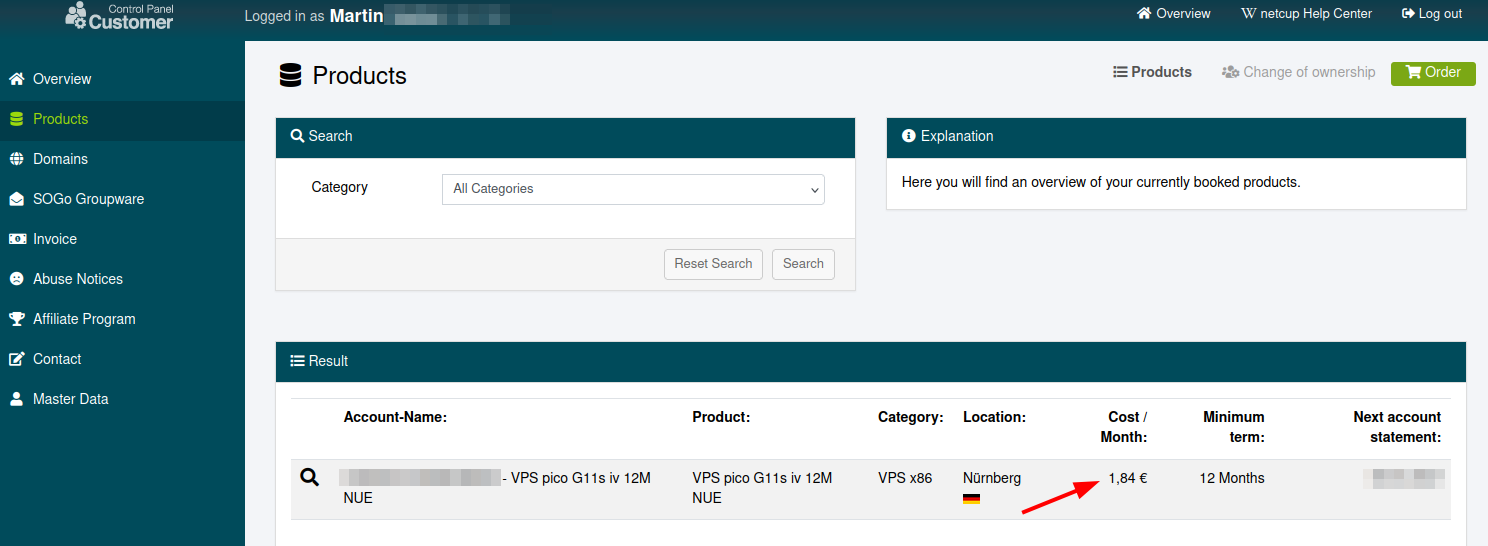
Over the years, I’ve moved more and more services I was hosting on Hetzner to other infrastructure providers due to pricing and interconnection issues. These days, only 2 small VMs remain but are now under scrutiny as well, as Hetzner has significantly increased prices for them. To make matters worse, such VMs are still advertised but often not available when I actually want to book them. So it was time to look for something else for small workloads that don’t require a lot of CPU power, RAM and storage.
Continue reading Netcup – Part 1: Tiny VMs For CheapScaleway Bare Metal Server: Removing the RAID
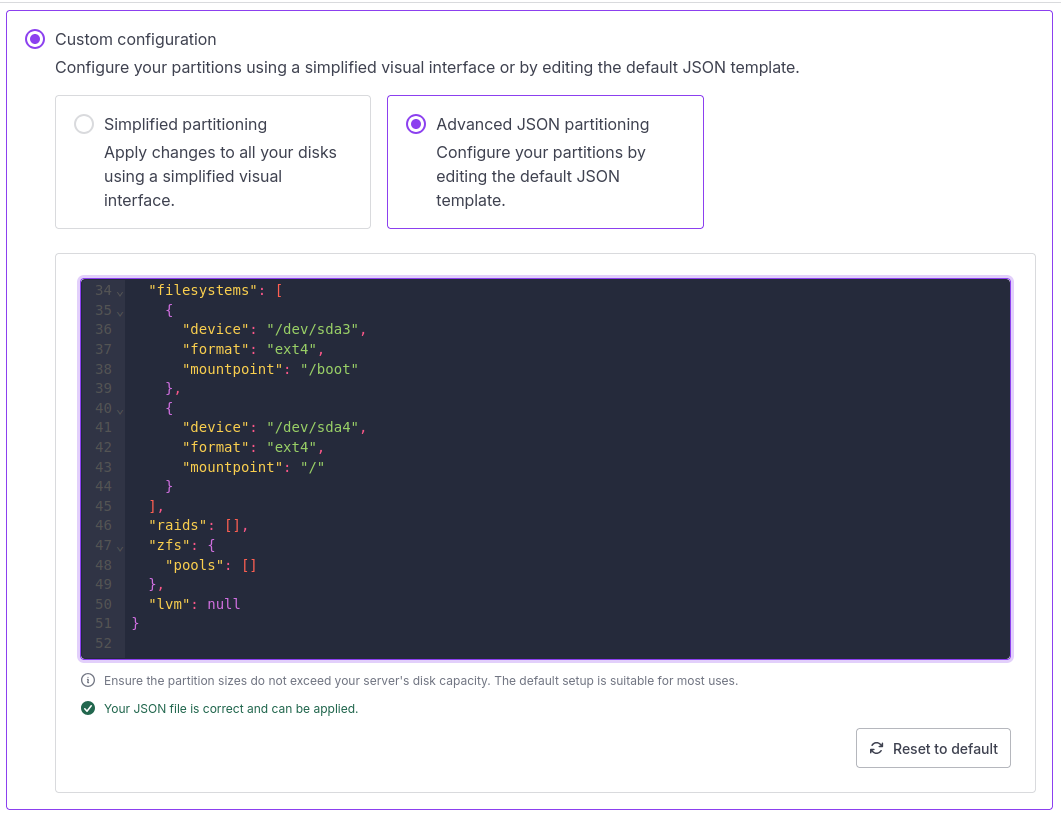
Back in 2024 I moved most of my services from a bare metal server in a data center of one provider to a bare metal server in a data center of another provider. In my case, the data center I migrated to was Scaleway and like pretty much everyone else, their bare metal servers are configured by default with two drives and a RAID for redundancy. As I required more storage then the RAID could provide, I removed the RAID configuration after I installed Ubuntu as the host operating system. You can find the somewhat complicated details here. But it turns out there is actually a much simpler way: A custom partitioning config file!
Continue reading Scaleway Bare Metal Server: Removing the RAIDOpus and the Jitter Buffer – OTT Voice Observations – Part 5
In the previous posts on this topic I have taken a look at ‘over the top’ voice calling, how much jitter IP packets have when they arrive at the destination and which codec is used. Most over the top voice call options seem to use WebRTC as a general framework for the voice call, and WebRTC in turn uses the free Opus codec to transmit the speech path. Opus in turn uses the NetEQ jitter buffer framework to adapt to changing network conditions. So what does that mean?
Continue reading Opus and the Jitter Buffer – OTT Voice Observations – Part 5Ubuntu 26.04 – An Encrypted Separate Home Partition – Part 2
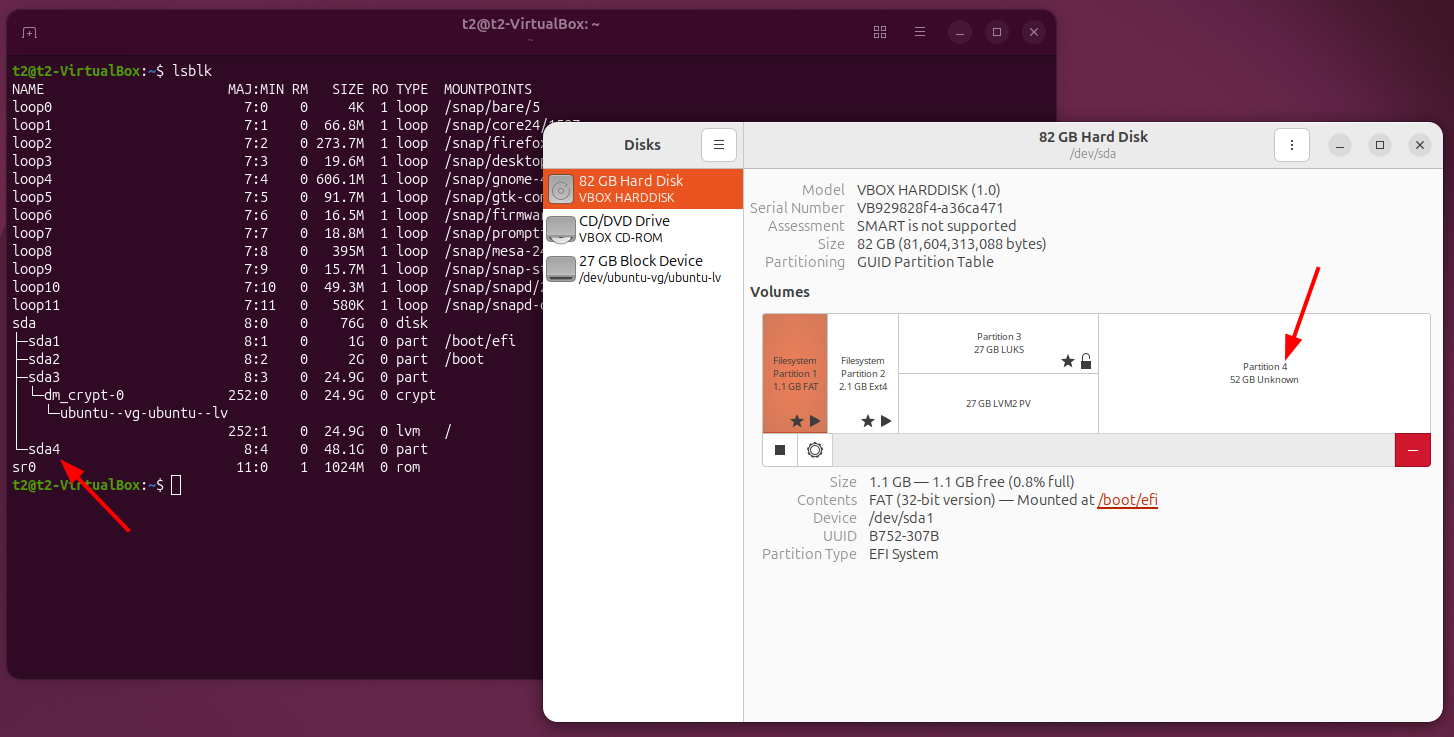
In the previous post, I’ve had a look at how to create a new Ubuntu 26.04 installation with an encrypted system partition and a separate partition for the user directory that is also encrypted. A cool way to get this done is to bring up an installation in a virtual machine first and then move a copy of it to a physical computer. While this is my installation and configuration method of choice going forward, I have now also found out now how to do this directly on a physical device.
Continue reading Ubuntu 26.04 – An Encrypted Separate Home Partition – Part 2XMPP Voice Call Setup Tracing – OTT Voice Observations – Part 4
In the previous post, I’ve had a look at how the voice calls codec and other parameters are exchanged and negotiated between two XMPP clients such as the Conversations messenger running on Android. As I operate my own XMPP server, I can trace right in the middle and while there is end to end encryption for message content and voice calls, most parts of the signaling message for a voice call setup are going through the server in plain text. I use the Prosody XMPP server and there are several ways to trace there:
Continue reading XMPP Voice Call Setup Tracing – OTT Voice Observations – Part 4Which Voice Codec? OTT Voice Observations – Part 3
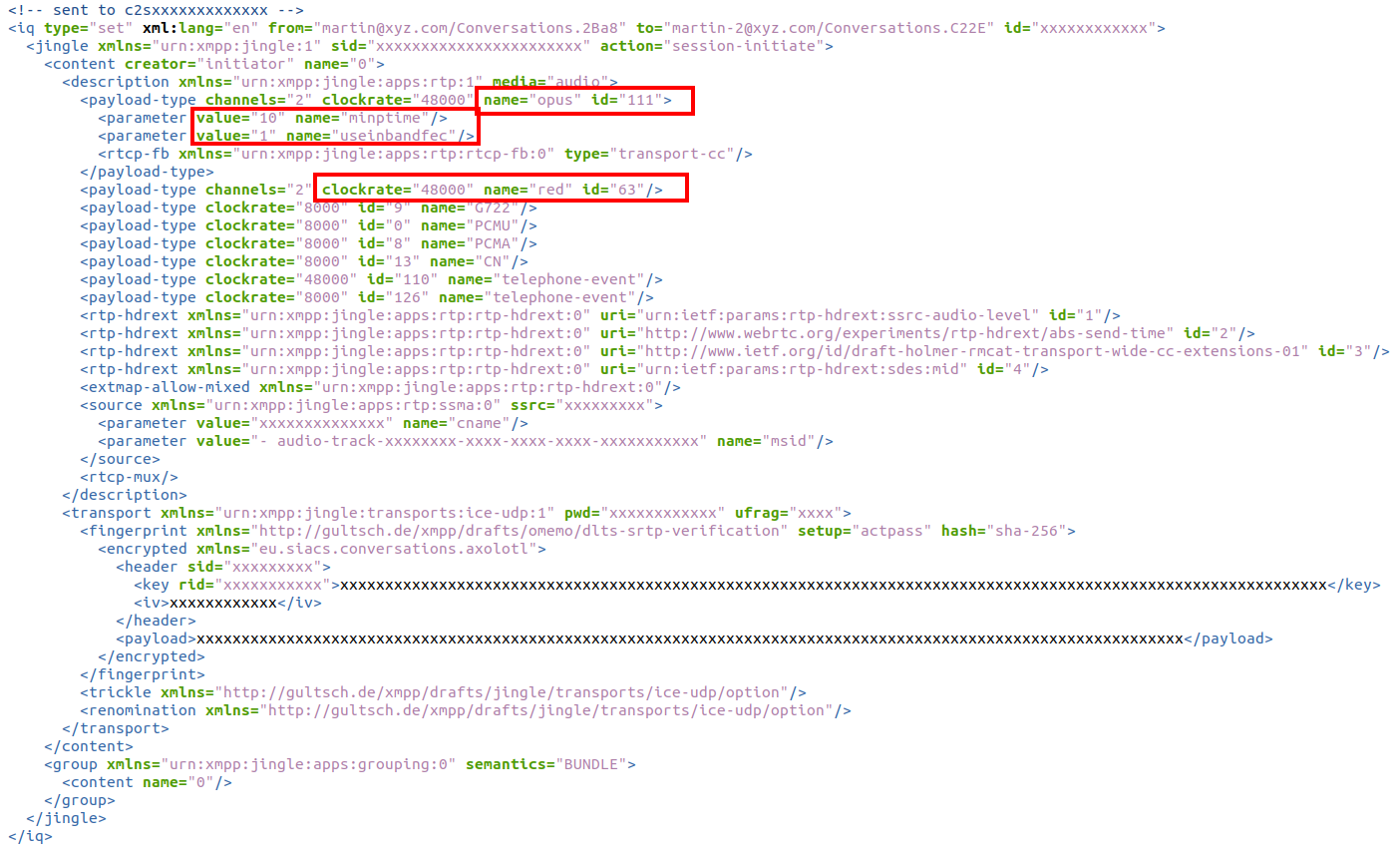
In part 1 and 2 on this topic, I’ve been looking at how over the top voice services such as the Signal messenger or the Conversations messenger packetize and send data over the cellular network and the resulting graphs look pretty neat. But which codec is actually used for the voice channel? I’ve been looking a bit into the source code of both messengers and both use WebRTC for the voice channel. But which voice codec is actually negotiated? The Internet ‘knows’ that Opus is used, but is that really so? I decided to have a closer look.
Continue reading Which Voice Codec? OTT Voice Observations – Part 3Ubuntu 26.04 – An Encrypted Separate Home Partition
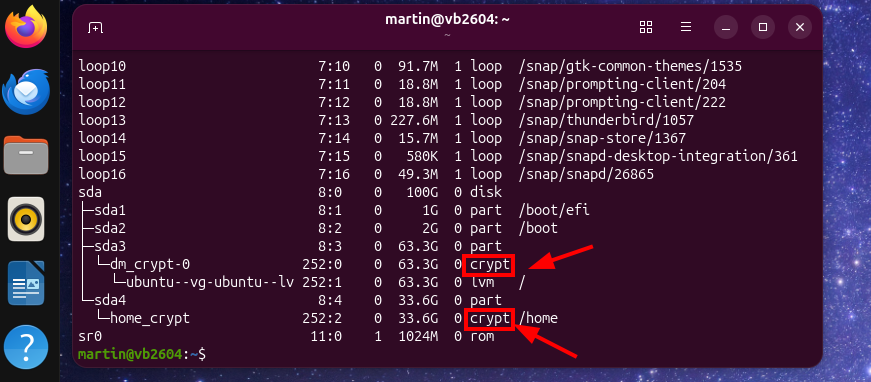
I’m still running on Ubuntu 22.04 and it’s time to upgrade to something more recent after the release of Ubuntu 26.04 earlier this year. I’ve decided to start with a clean installation and make a number of improvements to my setup. So far, I’m using an ext4 system partition and a separate ext4 LUKS encrypted partition for the home directory. The benefit of this is that I can use Clonezilla to quickly back-up or copy the relatively small boot and system partitions and restore them on another SSD. This gives me a working system in a few minutes that is configured exactly as I want it, and I can then restore the home partition that holds more than 1.5 TB of data at my leisure. The problem: The system partition is not encrypted, which I have compensated so far by using the SSD hardware encryption with a password on power-on. This works for me, but an encrypted system partition would be even better. The challenge: The Ubuntu desktop installer does not have an option to create a system with separate system and home partitions and encrypt them both. A pity. But with the experience gained by experimenting with installing, backing-up and restoring physical SSDs to virtual machines and vice versa over the past years, I have found an elegant solution:
Continue reading Ubuntu 26.04 – An Encrypted Separate Home Partition