I’ve thoroughly dockerized the services I run in my cloud at home and in a data center over the past months. However, at last count, there are still over 25 servers and virtual machines running on which I run various services. I don’t have a problem with that, but keeping them all updated and rebooted is not a very exciting task. So perhaps Ansible is the tool for automating my cloud updates?
The Status Quo
Until now I’ve used the ‘terminator’ shell to enter shell commands to many servers simultaneously and observe their responses. That works great even with 20+ machines, but tasks such as monthly software updates and reboots still take quite some time and attention.
In many cases, people use the package manager’s auto-update feature to keep their servers and virtual machines updated. In my cloud, however, I’ve deactivated the feature on most VMs, as I like to know when updates are done and what happens during the process. But admittedly, I haven’t encountered a serious issue over many years so I might as well switch on auto-update. I haven’t done it so far because every now and then, updates want to overwrite config files that I have changed and ask what is to be done during the process. As I don’t want to loose my changes, I opt for keeping the current file when asked. Over the years, I’ve been wondering what auto-updates would do in such a case and if this would be in the way of automating my manually triggered updates.
So I’ve come to the point where I was ok to put the software updates of my servers into the hands of a tool. There are a number of tools available for the purpose and I decided to give Ansible a try. Apart from its popularity, I noticed that Ansible is agent-less, i.e. no software needs to be installed on the servers that are managed via Ansible. Ssh access and Python is all that is needed on the managed machines. The only machine on which Ansible needs to be installed is on my notebook and is done with a simple ‘apt install ansible’.
So here’s how Ansible works in 30 seconds
Ansible uses text files in which tasks are described that are to be executed either locally, on a remote server, or on many remote servers simultaneously. These text files are referred to as ‘playbooks’. The IP addresses or domain names of servers on which actions are to be performed can be described in this or a separate text file. Separating the instructions from the server information makes sense, so playbooks can be reused.
Some Fun with Updates
Here’s how a simple playbook looks like to run a software update on remote (Debian based) servers:
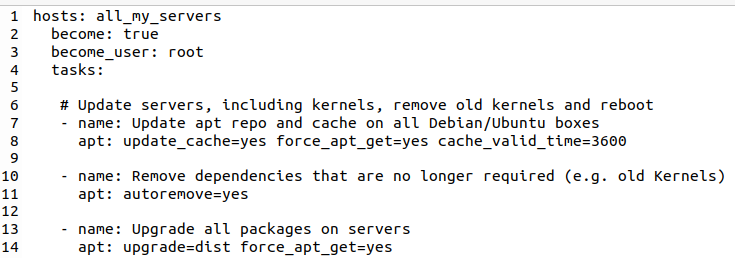
The playbook starts with a ‘hosts’ instruction that references a group of servers in another file (more about that later). It then goes on to describe that Ansible shall ssh into the servers, become root and then run three tasks. Each task has a user defined name. In the example above, the built-in ‘apt‘ module is called to do an ‘apt (cache) update‘, followed by an ‘apt autoremove‘ to delete old kernels, and finally the upgrade. And that’s already it, 14 lines will run a simultaneous software update on all my servers.
One thing I was a bit apprehensive about was how Ansible manages upgrades in which a package update wants to overwrite a user modified configuration file. When done manually, one has to confirm or deny the action before the update proceeds. So I had a look at how Ansible performs the upgrade command (with the super verbose -vvv option) and saw that it requests apt to leave modified configuration files in place. I hope that works in practice, I have yet to find out. But o.k., that will do it for me.
Especially when the kernel is updated, a reboot of the server is required after the update. Ansible can do that, too. Here’s the task that reboots the server, depending on whether a reboot is required or not:
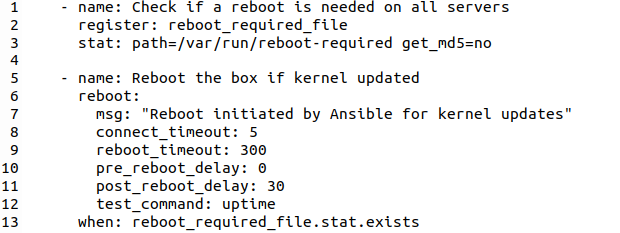
These instructions require a bit of an explanation. The first part checks if /var/run/reboot-required has been created in the file system by the apt update process. If so, it sets (registers) a variable (reboot_required_file). This is picked up by the next instruction (reboot) which is only executed (when:) the reboot_required_file variable exists. Actually, this variable contains a Json struct that contains a number of attributes, and the ‘when:‘ condition checks if the ‘stat‘ attribute exists within the Json structure. If a reboot is required, Ansible’s reboot module does more than just reboot the server, it also waits and checks if it has come up again.
Even more fun with updates
The actions above are those that I’ve done manually so far. But while I was at it, I wanted to add a number of other steps to the process. For one thing, I wanted a check if all servers are reachable before I started the update procedure. Also, I wanted to know if there is enough disk space available. Here’s how the Ansible tasks for these two steps look like:
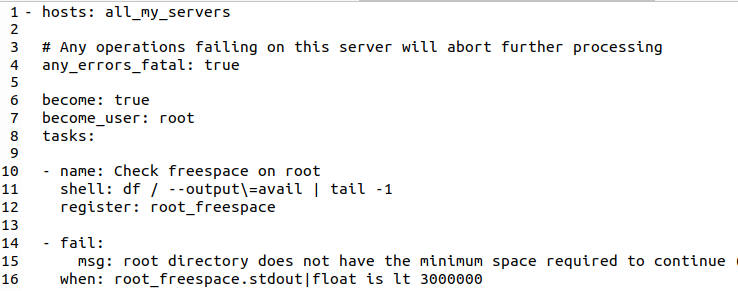
The first task runs a shell command on the remote server(s) to gather the available disk space on the system partition (‘/’). The result is put into the root_freespace variable / Json struct.
The second task is a ‘fail’ task. It is executed if the value of the root_freespace stdout attribute contains a value of less than 3 GB. Note how Ansible allows conversion of the text string to float and the comparison (‘ is lt ‘). What I want in case of a failure is that the complete operation is aborted, I don’t want any updates to happen. This is achieved by setting the ‘any_errors_fatal‘ instructions at the beginning of the hosts section to true. So if even only one of the servers I want to upgrade does not have enough disk space, none of them will be upgraded and Ansible will terminate the playbook immediately.
Canaries
And finally, I need a number of fail-safes, because I don’t want all my servers to end up in a weird state in case there is a problem with the update. Yes, I have never experienced this before but it’s better to be save than sorry. So instead of upgrading all servers at the same time, I have a ‘hosts‘ section in which I update only a few servers and have set the ‘any_errors_fatal‘ to true for this section. In other words, Ansible will stop if it detects an update error in any of those canary hosts.
And to be even more save, I have put an instruction into my playbook to pause after the canary servers are updated, so I can check them, and only proceed to update the rest of my servers once I give the go-ahead. This looks as follows:

Once I confirm by pressing the enter key, the remaining servers are updated. As a lot of virtual machines run on the same server, I have several update sections to stagger execution. That means that the same tasks are repeatedly used. So instead of putting the same lines of instructions several times in the playbook, I import a task file several times. Not only does this make the playbook shorter, but changes in the update procedure that might be required in the future have to be made only once. In other words, those includes are like ‘function’ calls in programming languages.
So far, I’ve spent a day going through the Ansible documentation and posts of people to put the pieces for this together. Agreed, I could have done a lot of software updates in this time. However, I learned a lot, and I already have a list of other things I want to automate with it in the future, so it was time well spent. And in case you are interested, I’ve put my playbook files on Codeberg for you to explore.