In part 3 of this series, I’ve found the reason of why that FTTH line to Paris is so slow to download data from most destinations: Excessive packet loss. While I still haven’t found the reasons for the packet loss, I could at least answer why some (but very few) servers do not have a problem with it. And in the process, I figured out how to increase the throughput from one of my servers on the Internet to a client behind that FTTH line from 40 Mbps to 800 Mbps!
TCP and Packet Loss
One of the feedback mechanisms used by TCP/IP to detect congestion or the maximum line rate of a connection are missing packets. When a client receives a TCP packet during a download with a sequence number that is higher than it should be, it sends a DUP(-licate) Acknowledgement to request the sender to retransmit the missing packet. Most TCP implementations take this as an indication of congestion and reduce their output. There can of course be other reasons for missing packets apart from reaching the capacity of a link and hence the router throwing away packets. These are for example packet reordering, which seems to happen seldomly, or missing packets due to broken hardware, or an incompatibility between network devices such as a computer and an Ethernet switch. I guess the excessive packet loss that slows me down is due to a hardware problem or incompatibility somewhere along the line, but that still needs to be determined.
TCK and ACK Round Trips
So back to that server that delivers its data to me at 800 Mbps. At first I thought that there might be no packet loss between us, but a Wireshark trace quickly revealed that this is not the case. Packet loss on the line from this server is even more excessive. But for some reason, the server does not care at all. But why!? At this point it was time to brush up my knowledge on TCP/IP throughput handling. Packet Loss is one of the indicators TCP uses that too much data is pumped into the network. The other indicator for TCP if things are going well or not is the round trip delay time of a packet being sent out and an ACK packet received for it or a subsequent packet. If the round trip time between data sent and the ACK coming in gets shorter, this indicates that there might be unused capacity that can be filled on the links between the sender and the receiver. If the round trip time increases, it means that data starts to get buffered on routers in the network and hence TCP needs to start throttling down. If it doesn’t do this fast enough or if traffic from some other source suddenly increases load on the network significantly, packet loss occurs. So the packet loss is kind of a late warning sign rather than an early one.
TCP Congestion Control Algorithms
TCP uses an internal congestion window (CWND) to control its transmission rate. The congestion window must not be confused with the the TCP window size that is continuously communicated from the TCP client to the server so it doesn’t get overwhelmed by incoming traffic. But suffice it to say at this point that the congestion window must not become greater than the TCP window advertised by the client. A good starting point to find out more about TCP congestion control is this Wikipedia article. As the article points out, TCP congestion control has evolved significantly over the past decades. And here comes the interesting point for my current packet loss / throughput dilemma: There are TCP congestion control algorithms which do not take packet loss into account at all. Yes, read that again, they don’t care about packet loss, they only look at round trip delay times during the data transfer.
So could that one server that is not impacted by the packet loss on my FTTH line use a different TCP congestion control algorithm than most other servers that is not impacted by the packet loss? I started to dig a bit into this and found out that it’s very easy to switch to a different algorithm in Linux. By default, Linux ships with a number of different algorithms which can be listed as follows:
> ls /lib/modules/uname -r/kernel/net/ipv4/tcp* /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_bbr.ko /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_bic.ko /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_cdg.ko [...] /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_vegas.ko /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_veno.ko /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_westwood.ko /lib/modules/5.4.0-109-generic/kernel/net/ipv4/tcp_yeah.ko
The list is actually a bit longer so I removed some lines in the middle. The currently used algorithm can be queried as follows:
> cat /proc/sys/net/ipv4/tcp_congestion_control cubic
By default, Linux uses the ‘CUBIC‘ algorithm for congestion control, which takes ACK round trip and packet loss into account. When reading up on the different algorithms, I noticed that the Bottleneck Bandwidth and Round-trip propagation time (BBR) algorithm designed by Google around 2016 only looks at the ACK round trip time and ignores packet loss. These days, BBR comes as part of my Ubuntu distribution and it can be set for use as follows:
echo "bbr" > /proc/sys/net/ipv4/tcp_congestion_control
And here’s what throughput looks like before and after ‘BBR’ is activated:
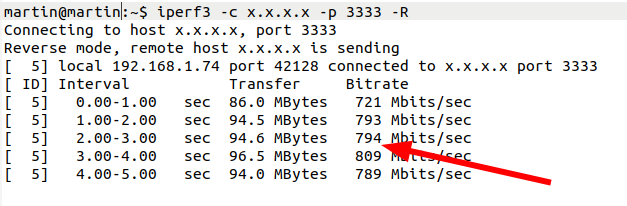
# iperf3 with packet loss and 'cubic' iperf3 -c x.x.x.x -p 3333 -R [...] [ ID] Interval Transfer Bitrate [ 5] 0.00-1.00 sec 9.59 MBytes 80.4 Mbits/sec [ 5] 1.00-2.00 sec 5.79 MBytes 48.5 Mbits/sec [ 5] 2.00-3.00 sec 5.32 MBytes 44.6 Mbits/sec [ 5] 3.00-4.00 sec 5.87 MBytes 49.2 Mbits/sec [ 5] 4.00-5.00 sec 5.39 MBytes 45.2 Mbits/sec # iperf3 with packet loss and 'bbr' iperf3 -c x.x.x.x -p 3333 -R [...] [ ID] Interval Transfer Bitrate [ 5] 0.00-1.00 sec 86.0 MBytes 721 Mbits/sec [ 5] 1.00-2.00 sec 95.1 MBytes 798 Mbits/sec [ 5] 2.00-3.00 sec 97.5 MBytes 818 Mbits/sec [ 5] 3.00-4.00 sec 93.6 MBytes 785 Mbits/sec [ 5] 4.00-5.00 sec 96.3 MBytes 807 Mbits/sec [ 5] 5.00-6.00 sec 97.6 MBytes 819 Mbits/sec
45 Mbps before and beyond 800 Mbps once BBR takes over the job. So despite massive packet loss, my data download runs at the FTTH line rate. Incredible. In the image below I’ve contrasted the the ‘CUBIC’ TCP sequence number flow with the ‘BBR’ TCP sequence flow on my high packet loss line.
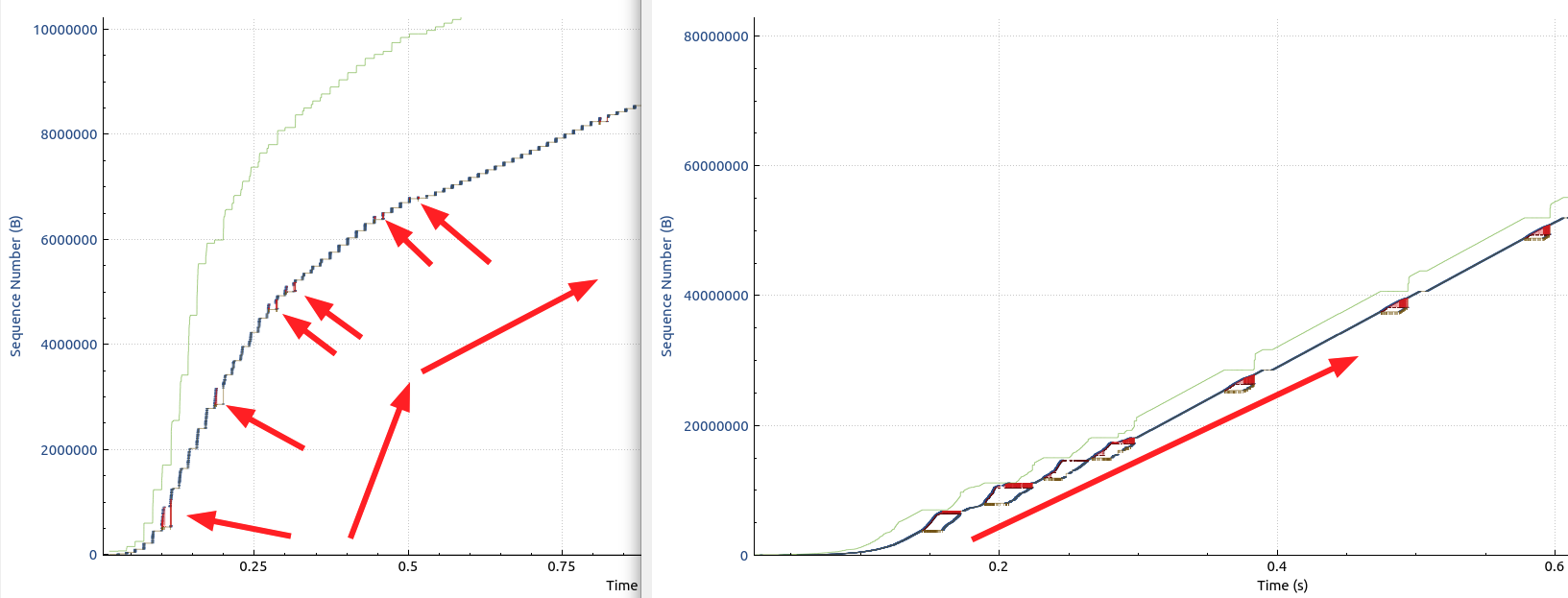
You might want to right click on the image and open the full size version of it in another tab. Let’s first have a look at the left graph, which shows the first 750 ms of the TCP downlink traffic on my high packet loss line with ‘CUBIC’. The arrows pointing towards the curve show where packet loss occurs. The occurrences are marked with small red lines which can be seen much better in the full size version of the image. These force the server on the Internet to throttle the transmission rate. This is why the curve that shows the progress of sequence numbers (i.e. the number of bytes transferred) starts to flatten almost immediately. In effect, this reduces the transfer speed to 1/20th of the line rate, i.e. to 40 Mbps. This ‘flattening’ is shown with the two arrows pointing upwards.
Now have a look at the right side of the image. This is the curve when ‘BBR’ is activated on the server side. Here, packet loss is even more pronounced, the red spots can clearly be seen. And it’s apparent that the packet loss has zero impact on the transmission rate. BBR cuts right through them, only orienting itself on the round trip delay times between data packets and their ACKs in the reverse direction. Don’t be mislead by the right curve looking shallower than the curve on the right. Have a look at the x-axis. The sequence number count is an order of magnitude higher in the right diagram than in the left! This is really stunning and really blew me away. I did not expect such an incredible improvement!
So Does BBR Fix My Problem?
When looking at the Wireshark trace of that other server that could deliver data at 800 Mbps, I saw exactly the same behavior. So it’s clear, that server also uses BBR. So does that fix my problem? Unfortunately it does not, because the TCP algorithm change has to be done on the server side. In other words, I don’t have control over this, and I still need to find the source of the excessive packet loss and fix it. But looking on the bright side, this issue has pushed me to brush up my TCP congestion behavior knowledge, gave me incredible insight and I’m sure this new knowledge will become useful in the not too distant future.
Resources for Digging Deeper
If you want to dig deeper, here are two cool resources:
- Chris Greer talks about TCP congestion control in this 15 minute video
- A 1.5h talk on the same topic with super interesting details by Vladimir Gerasimov at Sharkfest 2019