I’m old school, I like locally attached block devices for data storage. Agreed, we are living in the age of cloud, but so far, the amount of data I store cloud at home and in data centers could always be placed on block devices, i.e. flash drives directly connected to that server. Recently, however, I’ve been thinking a bit about how to store images and videos in the cloud and how to upload and synchronize such data from different devices. That means that a few hundred gigabyte will definitely not do anymore, we are quickly talking about TBs here. Locally attached or network block storage in a data center of such a magnitude is quite expensive, we are talking 50 to 100 euros a month per TB. But perhaps there is another option? Many cloud providers also offer S3 compatible object storage today at one tenth of the cost, i.e. €6 per TB per month. Could that be an alternative?
The photo and video storage application I have in mind (more about that in a separate post) uses a plain file system to store data files and the database. So would it be possible to use S3 object storage and bind it to a path in the file system? A quick search gave me a ‘potential’ yes with lots of question marks attached. In other words, I gave it a try to see how easy it would be to set this up and what the performance would look like.
For my tests, I used the S3 compatible object store offer of Scaleway. It’s not the cheapest one around, Hetzner might have a better offer, but it’s close to my bare metal server, which I also host there. There’s a good explanation of how to get started on their website, and here’s my summary for a quick start:
Create the Bucket
First, create a ‘bucket’ that with a capacity in GB of your choice in the ‘Object Storage’ section and give it a name. For this blog post, I’ve called it MARTIN-BUCKET. Once done, files can then be up- and downloaded into the bucket. For remote access, the bucket is private, and an ‘access key‘ and a ‘secret key‘ are required to access the bucket.
Create Access and Secret Keys
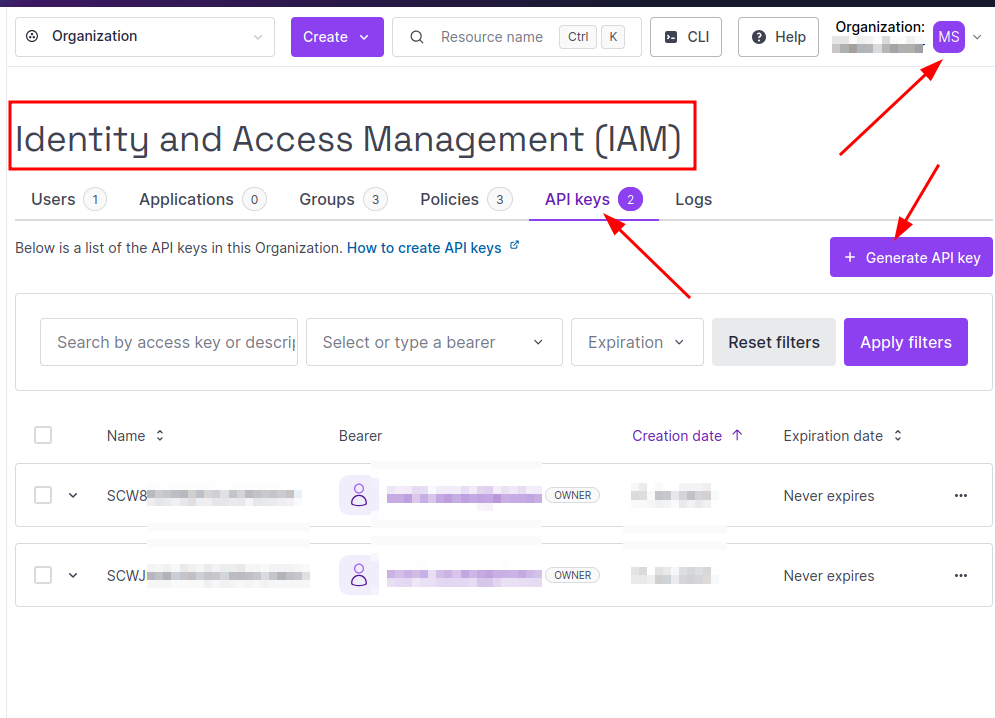
Generating an access and secret key is simple, if you know where to look. In Scaleway’s case, a key pair can be created via the ‘Organization‘ menu at the top right of the admin center page in the ‘API Keys‘ menu entry. Click on ‘+ Generate API key‘ and check the radio button ‘Will this API key be used for Object Storage‘.
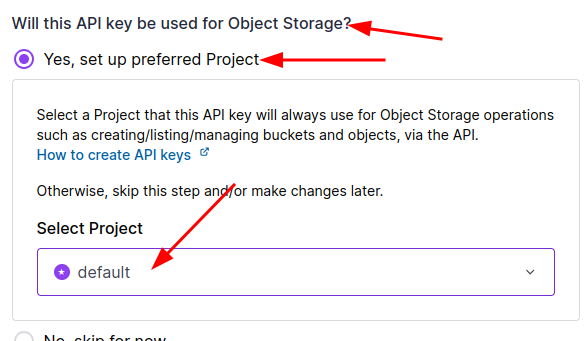
In ‘Select Project‘, enable the ‘default‘ project. I don’t have a lot of infrastructure and resources with Scaleway, so I only have a ‘default’ project to which all my resources are bound, including the S3 bucket I created in the previous step.
Access the Bucket over the Network
How a bucket and keys for it are created are cloud provider specific, but everything that follows now is done with Linux S3 object storage command line tools that work with S3 storage of any vendor. This is important for me as I want to avoid cloud provider lock-in at any cost. That being said, the bucket and the objects (i.e. files) in it can be remotely accessed on the Linux command line as follows:
First, install the tools:
apt install s3cmdThen, create .s3cfg in your home directory and fill it with the following values:
[default]
host_base = s3.fr-par.scw.cloud
host_bucket = %(bucket).s3.fr-par.scw.cloud
bucket_location = fr-par
use_https = True
# Login credentials
access_key = SCW..................
secret_key = ..........................Depending on your S3 providers, the parameters will look different. At the end of the parameter list are the access_key and the secret_key which were generated in the previous step. Once the configuration file is in place, the bucket can now be accessed as follows:
# List objects, i.e. files
#
s3cmd ls s3://MARTIN-BUCKET
# Info on an object. The md5 sum is interesting to compare!
#
s3cmd info s3://MARTIN-BUCKET/1GB.bin
# Download (get) a file, e.g. test.txt
#
s3cmd get s3://MARTIN-BUCKET/test.txt
# Upload (put) a file, recursive uploads all files in local dir
#
s3cmd put --recursive . s3://MARTIN-BUCKET
# Use -f -d in the commands for debug output in case
# there is no output or an error
#
s3cmd -f -d get s3://MARTIN-BUCKET/test.txt
Speed
So far so good, so how fast is this? To check the raw data speed for transferring large files, I put a number of files there with randomized content and a size of 1 GB and transferred them to and from a virtual machine on my bare metal server in Scaleway’s data center. The result: The download of a 1 GB file ran at around 35 MB/s, the upload back into the object store ran at 25 MB/s. That’s way below the 1 GB/s line rate of the Ethernet interface.
I then started a virtual machine in a different data center of a different cloud provider on the other side of Europe and ran the same test again. Data rates were pretty much the same. Interesting, it doesn’t really mater if data was sent inside the datacenter or to/from the outside. At least not from a speed point of view. S3 data being sent outside the data center is billed, while data center internal data transfers are free in Scaleway’s offer. Other cloud providers may have different billing schemes.
And finally, I transferred the 1 GB file to and from my notebook at home and could achieve the data rates offered by my VDSL connection, i.e. 100 Mbps in the downlink direction and 40 Mbps in the uplink direction. I got the full line rate, so for such a scenario, it would be ok.
Next, I had a look at how fast a large amount of 2 MB files could be transferred. This would be a typical file size for my image storage application. The result: 100 files, each with a size of 2 MB were transferred in around 38 seconds, i.e. at 5.2 MB per second and 2.5 files per second.
S3 into the File System
Already at this point I came to the conclusion that S3 object storage is probably not going to be the right solution for my application, it’s too slow. But still I pressed on and mounted my bucket into my local file system on the notebook:
# create .passwd-s3fs in the home directory and put
# the access key separated with a ':' from the secret
# key inside.
cd; mkdir s3mnt
s3fs MARTIN-BUCKET /home/martin/s3mnt/ \
-o allow_other \
-o passwd_file=$HOME/.passwd-s3fs \
-o use_path_request_style \
-o endpoint=fr-par \
-o parallel_count=15 \
-o multipart_size=128 \
-o nocopyapi \
-o url=https://s3.fr-par.scw.cloud
# If this doesn't work straight away, use '-f -d' to enable
# debug outputThe ‘allow other’ option did not work out of the box, it required extra configuration in the fuse configuration file. But it can probably be left out. After a bit of trial and error, I could access the ‘objects’ in the bucket from /home/martin/s3mnt and copy files to and from the bucket on the command line.
Next, I used the Nemo / Naultilus graphical file explorer to have a look at the directory. And here came the big surprise: It took forever to show the directory listing. It eventually shows up but it takes many minutes. I soon noticed this was because for some reason, the file explorer opens all files, which then triggers a download of each file. As I had a couple of 1 GB files in my bucket, this took forever.
I then had a look if there are other open source graphical tools available to view the objects (files) in a bucket and copy data back and forth. It turns out that there is little choice, it doesn’t seem to be a thing. Very strange!?
Summary
At this point it became pretty clear to me that S3 object storage is not going to be a solution for my photo storage project, it is way too slow. Consequently, I didn’t take the next step to see if gocryptfs would be a good way to encrypt my files before sending them to public S3 storage. Too bad, but at least I gained a lot of knowledge while trying things out, and I already have another use case where these limitations might not matter. More about that in another post.