Continuing my mini-series on how VoLTE works in practice I’ve recently taken a closer look at how DTMF tones are transported over IMS. You might argue that DTMF tones are old technology but they are still used a lot today. Examples are entering the PIN to your voicemail system from the phone or sending a conference bridge ID and password over an established connection. In ‘good old’ analog telephone networks DTMF tones were generated by the phone itself and sent as an audible tone over the speech channel. In GSM and UMTS networks things changed and DTMF start and stop indications were transmitted as signaling messages to be interpreted and converted into a real tone in the network. In VoLTE, things have again been implemented differently.
VoLTE actually uses a mix of analog in-band and digital signaling messages. Instead of sending a message to the other end to produce a tone over the signalling path, VoLTE embeds the signaling message in the RTP (Real-time Transport Protocol) media flow by replacing RTP speech packets with RTP DTMF signaling messages. Usually 20 ms of speech data are contained in each RTP packet that is sent over UDP. Therefore to send DTMF tones, a DTMF signaling message has to be sent every 20 milliseconds instead of a voice packet. GSMA IR.92 points to 3GPP TS 26.114 Annex G which in turn points to RFC 4733 for the details.
When the RTP DTMF signaling messages arrive at a terminating VoLTE device, it’s the device’s responsibility to produce an audible tone for the user. If the terminator is not a VoLTE device, a media gateway is required to transcode the speech path into a codec suitable for the terminating network and the terminating device. As a consequence the media gateway is then responsible to convert the RTP DTMF messages into an audible tone and to inject it into the speech path data stream.
The two screenshots below give a good idea how things look like in practice. The first screenshot shows how a DTMF tone is embedded in an RTP packet while for comparison the second screenshot shows how a speech frame looks like in an RTP packet. I can see how this solution makes sense as everything is digital on the one hand while on the other hand the IMS signaling routers do not need to carry additional signaling messages.
Interesting side note: The “marker” field in the RTP header is usually set to 0. When a new DTMF digit starts, however, it is set to 1. This can be used as a convenient filter criteria in Wireshark to extract DTMF sequences.
 Screenshot 1: An RTP frame with an embedded DTMF signaling message that the user has pressed the digit ‘7’ on the dial pad.
Screenshot 1: An RTP frame with an embedded DTMF signaling message that the user has pressed the digit ‘7’ on the dial pad.
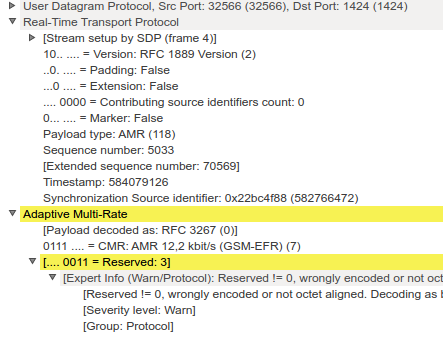 Screenshot 2: An RTP frame with Adaptive Mutli-Rate (AMR) speech data inside.
Screenshot 2: An RTP frame with Adaptive Mutli-Rate (AMR) speech data inside.
Indeed, a very interesting blog. Many people are not aware that in 3GPP technology DTMF tones are transferred via commands instead of just transmitting as a DTMF tone over the speech channel. Reason for this is that the speech codecs are optimised for speech and not for tones, the codecs would simply mangle the tones. Analogue to VoLTE and even in GSM, a speech frame is dropped in order to submit the DTMF commands in “real time”, i.e. DTMF was and is sent via the FACCH.