After the interesting throughput experiences I have made over the last mile, it was time to push the limit a bit and get an idea of how a high speed data transmission between virtual machines looks like that are in different data centers. While most of the public cloud infrastructure I used is located in Hetzner’s Helsinki data center, I do have a couple of virtual machines in Hetzner’s Nürnberg facility as well. In other words, an ideal setup to test inter-data center throughput.
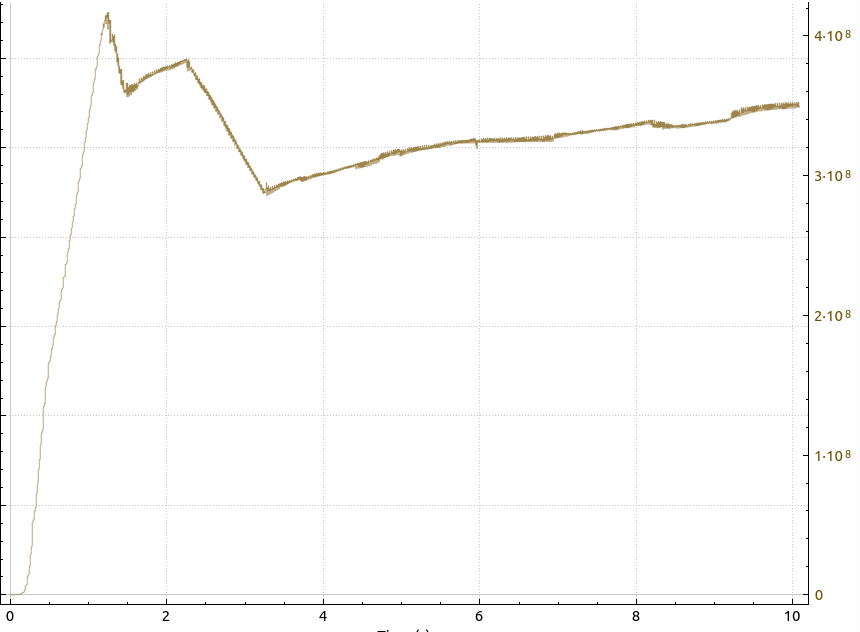
The image at the beginning of the post shows the throughput when transferring large amounts of data from a VM in Nürnberg to a VM in Helsinki. Both VMs are running on servers that are connected by 1GbE links to the backbone. That means that the bandwidth on that link has to be shared by all VMs on the physical server. So at first I was not surprised that I could ‘only’ get a throughput of around 300 to 400 Mbps. Or so I thought…
I then had a look at the TCP sequence number graph for this connection, and a part of it is shown in the following image:
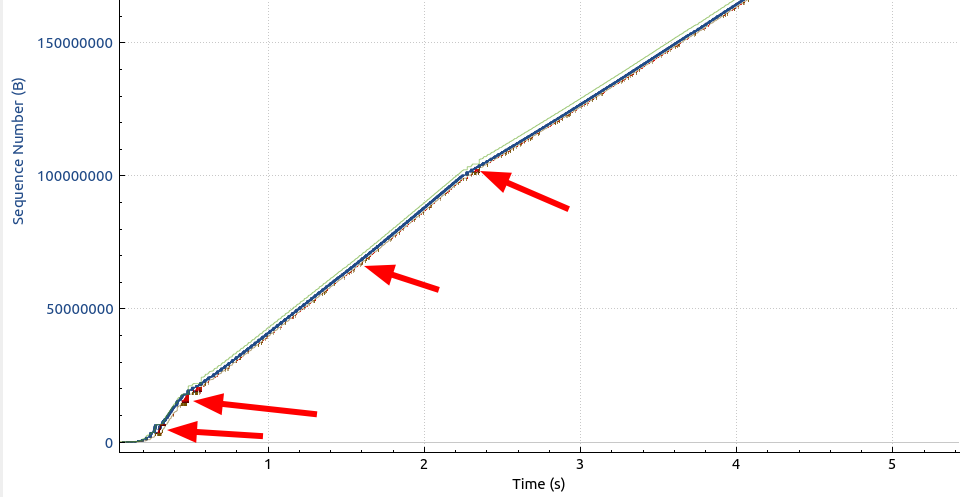
Even without zooming in further, the many packet losses immediately stand out (red dots and areas). While there are times with significant loss (1st, 2nd and 4th arrow from the left), there were also frequent single packet losses (3rd arrow from the left). So this is what limits the overall speed and for my taste, there is a bit much loss on the line. This reminded me a little bit of the packet losses I experienced in Paris, but not as pronounced or regular.
Hm, packet loss, I thought, there might be a fix for this: In Paris, I noticed that performance can be significantly improved by using BBR instead of the default Cubic TCP congestion control algorithm. And indeed, after activating BBR on the sender side, the throughput looked as follows:
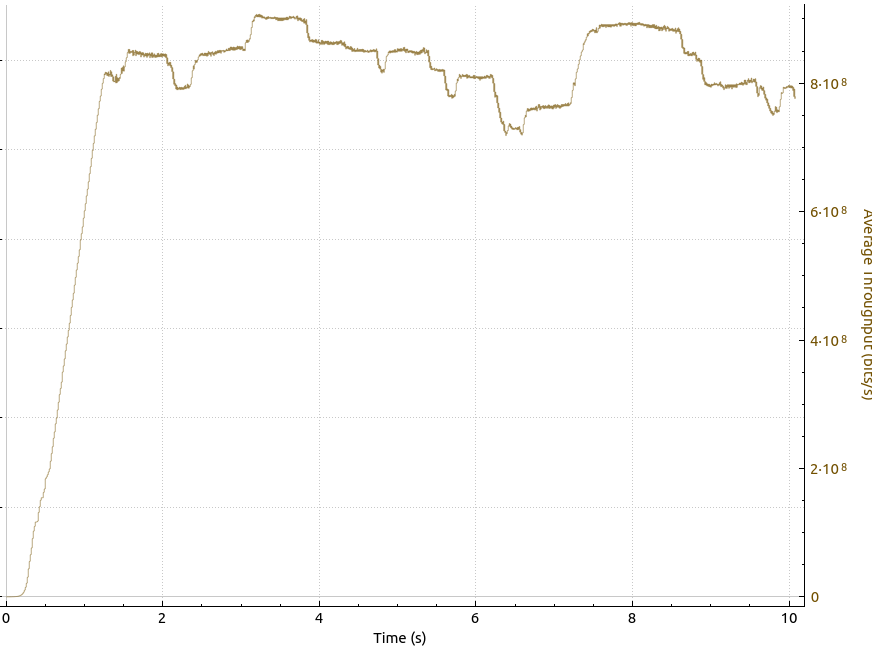
Wow, instead of 300 to 400 Mbps, I suddenly got around 800 on the line. Amazing! The packet drops are still there, but BBR just ignores them:
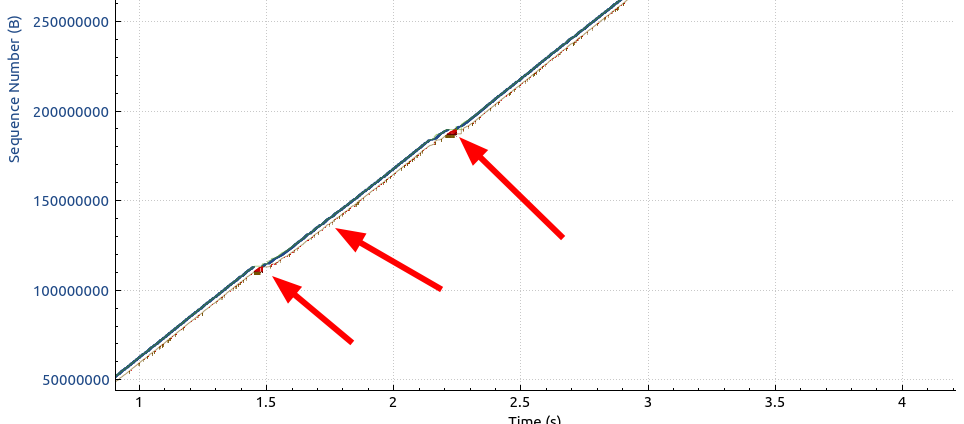
Note how the sequence number graph remains relatively straight with BBR, while the same graph above with CUBIC shows signs of flattening out whenever massive packet loss occurs.
The next thing I had a look at is how far away the bytes in flight are from the TCP receive window size. Here’s how that looks like:
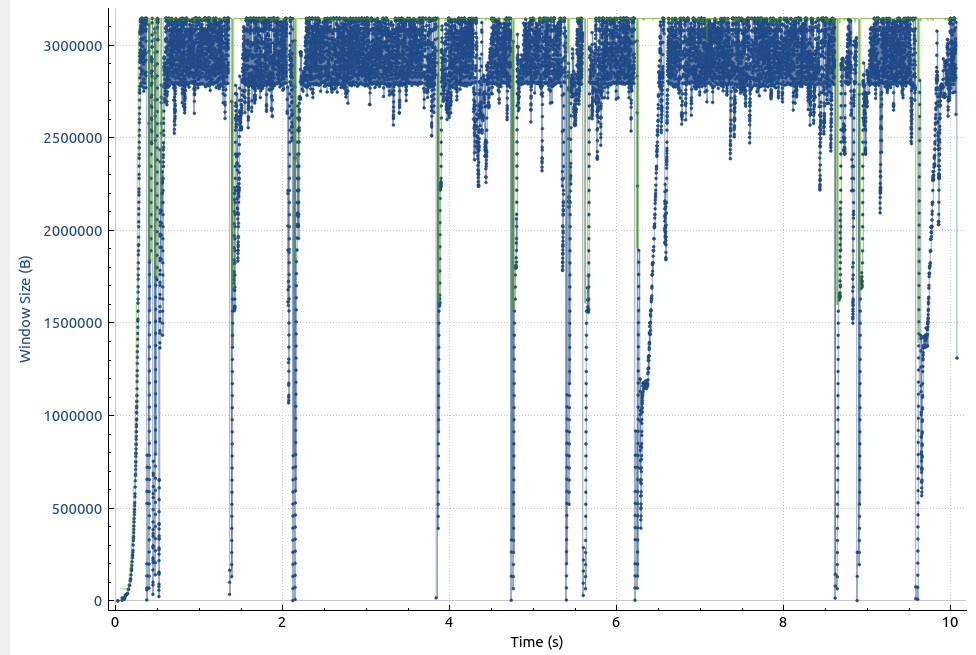
The blue dots are the bits in flight and the green line at around 3.000.000 bytes (3 MB) is the TCP receive window. Unfortunately, the bytes in flight frequently hit the maximum receive window size, so the transmission had to stop every now and then. A 3 MB TCP receive window sounds like a lot, so why were the bytes in flight frequently hitting it? The answer: The round trip delay time between the two servers during the high speed data transfer is in a band between 25 and 30 milliseconds, which, according to the bandwidth-delay product means, that there is around 3 MB of data in flight at any time.
After I increased the TCP receive window on the Helsinki VM to allow a 6 MB TCP receive buffer, the graph looks like this:
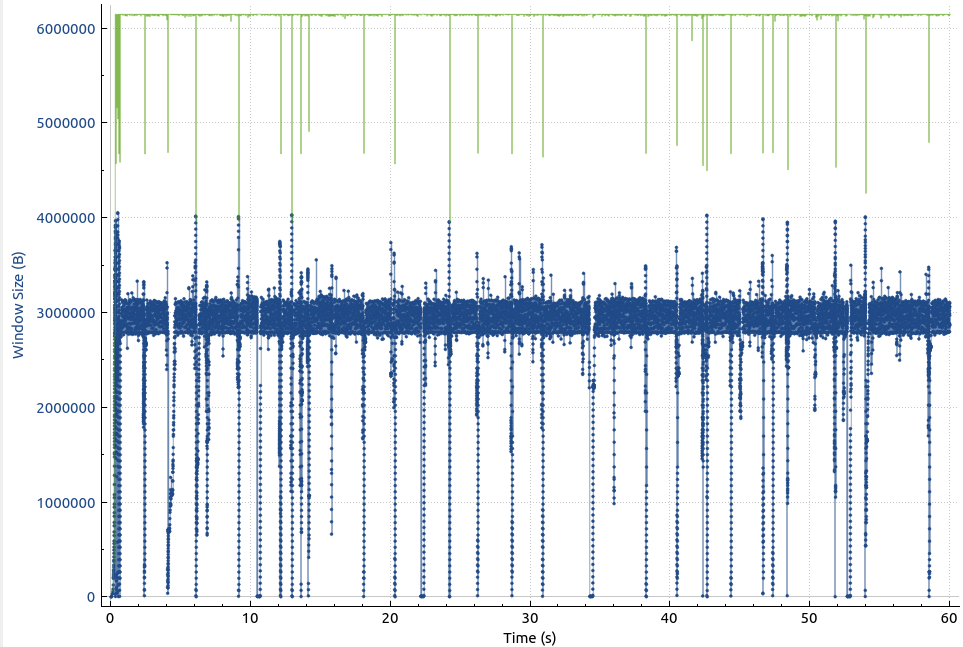
This looks a lot better, the number of bytes in flight are around 3 MB (blue line), which corresponds to the 25-30 ms round trip delay time in combination with a very high throughput. Speaking of very high throughput, this is how the graph looks like when the receive window is not reached:
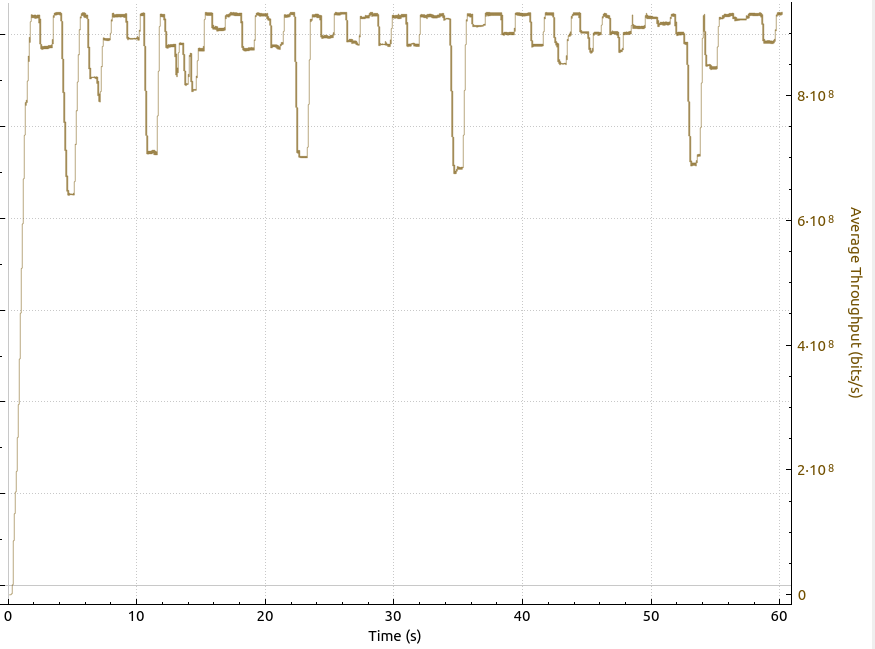
Wow, now we are talking! We are hitting 900 Mbps, which is 100 Mbps more than with the 3 MB TCP receive window and pretty close to what the 1 GbE link can theoretically provide.
Summary
While the default values of the TCP stack work well in most situations, they are not suitable for 1 Gbps data transfers between data centers with a relatively large round trip delay time and packet loss. But changing the TCP congestion avoidance algorithm from Cubic to BBR and increasing the TCP receive window to 6 MB significantly increased throughput from 300-400 Mbps to 900 Mbps. OK, this was well worth the effort!