In the past, I’ve always used KVM’s GUI to properly shut-down remote Virtual Machines when I needed to reboot the host and then re-launch them again after the reboot. Over time, this is a bit of a tiresome process, especially as the frequency of host reboots after security updates seems to increase. So at some point I thought that there must be an easier way to do this:
Continue reading Proper Shutdown of VMs on Host RebootTCP Tracing – Part 7 – Between Data Centers
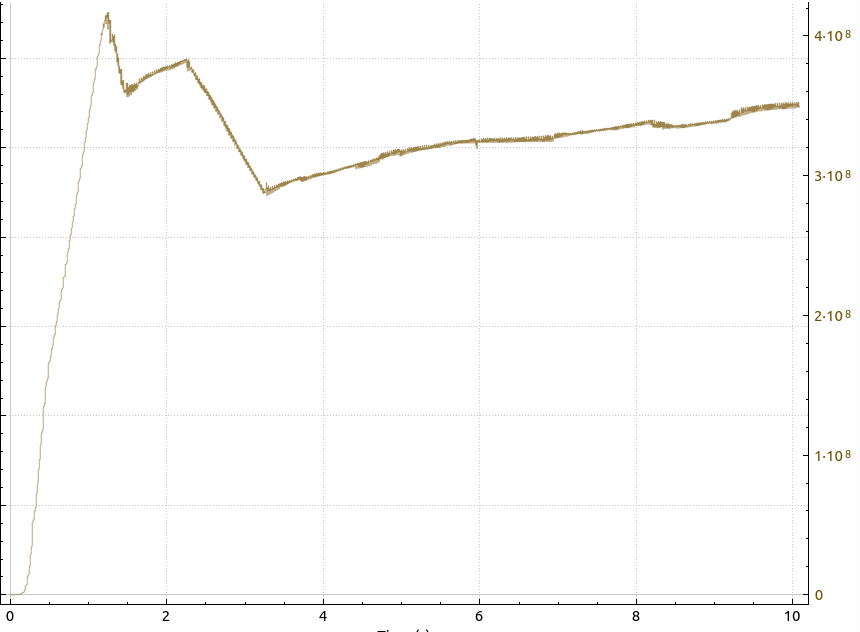
After the interesting throughput experiences I have made over the last mile, it was time to push the limit a bit and get an idea of how a high speed data transmission between virtual machines looks like that are in different data centers. While most of the public cloud infrastructure I used is located in Hetzner’s Helsinki data center, I do have a couple of virtual machines in Hetzner’s Nürnberg facility as well. In other words, an ideal setup to test inter-data center throughput.
The image at the beginning of the post shows the throughput when transferring large amounts of data from a VM in Nürnberg to a VM in Helsinki. Both VMs are running on servers that are connected by 1GbE links to the backbone. That means that the bandwidth on that link has to be shared by all VMs on the physical server. So at first I was not surprised that I could ‘only’ get a throughput of around 300 to 400 Mbps. Or so I thought…
Continue reading TCP Tracing – Part 7 – Between Data CentersZero Trust – The Elevator Pitch
Over the past few months I’ve heard the term “Zero Trust Networking” from time to time but I didn’t quite understand what was meant by the term. So I started to look into it a bit and here’s my elevator pitch for it:
Continue reading Zero Trust – The Elevator PitchTCP Tracing – Part 6 – Segmentation Offloading

With multi gigabit per second Ethernet and wireless interfaces, CPUs are quite challenged by the sheer number of packets that need to be handled. Let’s say a transmission on a (meager) 1 Gbps Ethernet link is well utilized by large file transfers (let’s say 100 MBbytes per second) and a typical maximum segment size (MSS) of 1460 bytes is used. That’s 68.493 packets per second in one direction, not even counting the TCP ACKs in the other direction! Also, Wireshark starts smoking when it has to look at a 60 seconds trace with 4 million packets inside. But there’s a fix for that with almost no downsides that: Segmentation Offloading.
Continue reading TCP Tracing – Part 6 – Segmentation OffloadingKubernetes Intro – Part 12 – Jaeger
It’s been a while since part 11 of my Kubernetes Intro, but new things keep coming. When you have a nice little Kubernetes cluster with dozens of interacting microservices running, you quickly come to the point where you need to debug the system. Today, and particularly in the telecoms networking world, tracing on network interfaces and analyzing the result with Wireshark is one of the most important debugging tools. But that’s a bit of a challenge when your signaling path flows through a Kubernetes cluster.
Continue reading Kubernetes Intro – Part 12 – JaegerTCP Tracing – Part 5 – High Speed Wi-Fi and the Receive Window
In part 4 of this series, I’ve compared the TCP behavior of high speed LTE and Wi-Fi to a virtual machine in a dater center over links with round trip delay times of around 25 ms. The results were very insightful but also raised new questions that I will follow up in this post. So here’s a quick recap of what happened so far to set things into context:
For fast Wi-Fi, I went to the local university in Cologne that has an excellent Eduroam Wi-Fi deployed in many areas. There, I was able to get an iperf uplink throughput of around 500 Mbps to a virtual machine in Nürnberg. When analyzing the TCP behavior in more detail, I noticed that my notebook quite frequently hit the default maximum TCP receive window size of 3 MB of the VM in the remote data center. In other words: More would perhaps have been possible with a bigger TCP receive buffer. So I gave this another try to see what would happen.
Continue reading TCP Tracing – Part 5 – High Speed Wi-Fi and the Receive WindowGet Notified of SSH Logins
Here’s a quick tip of the day that I came across when I needed a way to get a notification on my mobile device when particular users log into a server. Turns out that the Linux PAM (Pluggable Authentication Modules) offers a convenient way to do this:
Continue reading Get Notified of SSH LoginsTCP Tracing – Part 4 – Comparing LTE and Wi-Fi
In the first part of episode 3 on this topic, I have shown how throughput looks like in a good LTE network in which more than one user was activate at a time. I can’t be sure, but based on typical cellular scenarios, there were probably more than 30 concurrent active users in the cell. So I wondered how the throughput graph would look like in a 5 GHz Wi-Fi network with many users. A place with heavy Wi-Fi use are universities, so I decided to run a few throughput tests in an Eduroam Wi-Fi network. And here’s how the throughput of an iperf3 download from one of my servers to my notebook looked like:
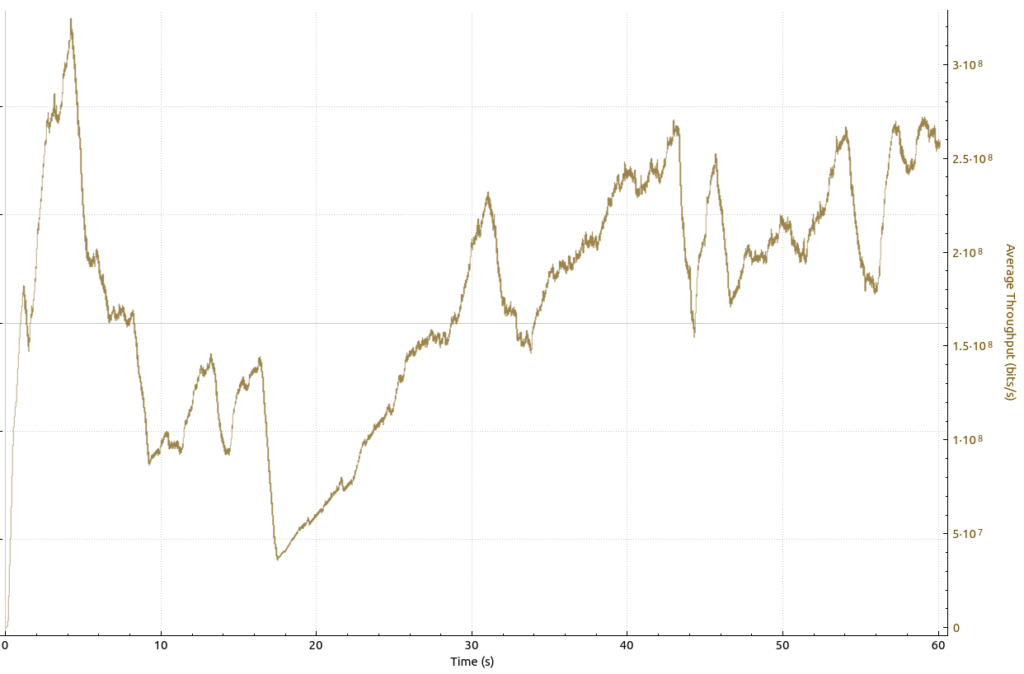
I took this throughput graph on a 5 GHz Wi-Fi channel on which the beacon frames announced that more than 50 devices were currently associated. As you can see, the throughput varied mostly between 150 and 300 Mbit/s, with a (single) short downwards dip to 50 Mbit/s. Overall, I’d say this is stellar performance in a relatively busy environment. Also, if you compare basic shapes and behavior of the transmission, this looks strikingly similar to the LTE throughput graph in the previous blog post on the topic.
But there is more…
Continue reading TCP Tracing – Part 4 – Comparing LTE and Wi-FiTCP Tracing – Part 3 – Unexpected Fluctuations in Belgium
In part 1 of this series, I compared how the TCP throughput graphs look like for a VDSL vs. an LTE link in stationary and mobility scenarios. Recently, I’ve been to Belgium for a few days and I was expecting to see pretty much the same LTE throughput behavior as in my home network. But it turned out that the graph looks entirely different there.
While I was in Belgium, my stationary scenario was in a location with relatively week signal strength, around -102 dBm. As it was pretty much in the countryside, I was limited to two LTE carriers, one on band 20 and one on band 3. As a reference, here’s a graph in similar network conditions in my home network in Cologne:
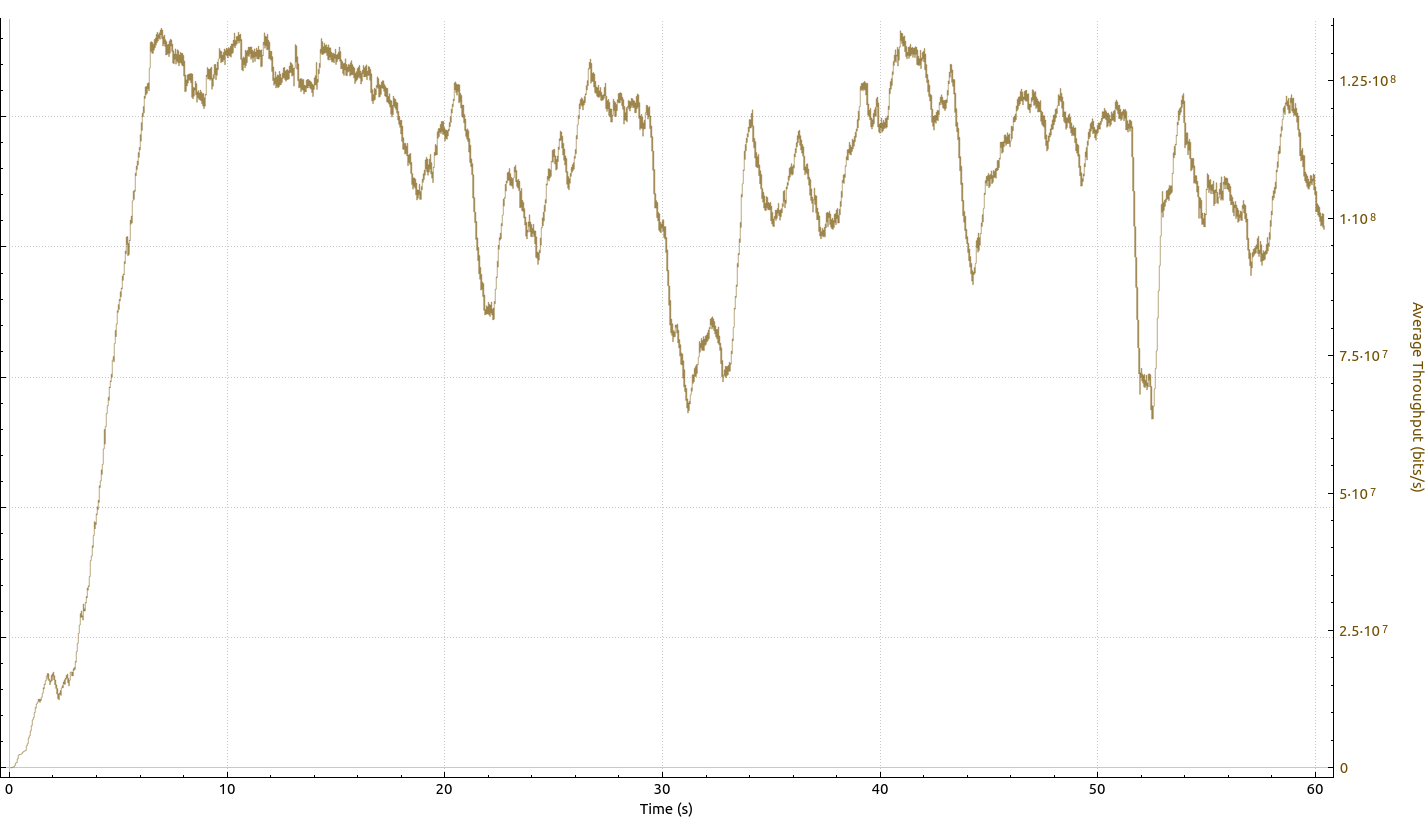
To me, this looks like a nice curve. I had 4 LTE carriers with low signal strength, and most of the time, throughput was well beyond 100 Mbit/s with only a few dips down to 75 Mbit/s.
And here’s the graph in the Belgian network I used:
Continue reading TCP Tracing – Part 3 – Unexpected Fluctuations in BelgiumTCP Tracing – Part 2 – Keep PCAP Sizes Reasonable
I’ve been doing quite some tracing on the TCP/IP layer recently and especially at higher speeds over links that support hundreds- to thousands of megabits per second, pcap dump files are getting rather large. Fortunately, both Wireshark and tcpdump offer an option to cut packets after a configurable length. That’s perfect for throughput tracing, as I’m only interested in what is happening on the TCP layer and not in the content of the packets. So here are the commands I usually use to dump large data transfers on an interface for later analysis:
Continue reading TCP Tracing – Part 2 – Keep PCAP Sizes Reasonable