In part 3 of this series, I’ve set-up my headless local LLM execution environment with Ollama so I’m ready for further experiments. One of the questions I wanted to answer with this setup is how much faster LLMs run on a GPU vs. the CPU. Part of the LLMs one can download is a configuration file that defines how the LLM is set-up for execution. One parameter in this file defines how many of the neuron layers of the LLM are to be executed on the GPU and how many of them should be run on the CPU. This is what is called ‘layer offloading’, and splitting up the work between the CPU and GPU can be useful when GPU memory is smaller than what is necessary to run the LLM on the GPU alone.
Continue reading My AI Learning Journey – Part 4 – GPU over CPU SpeedMy AI Learning Journey – Part 3 – LLMs at Home
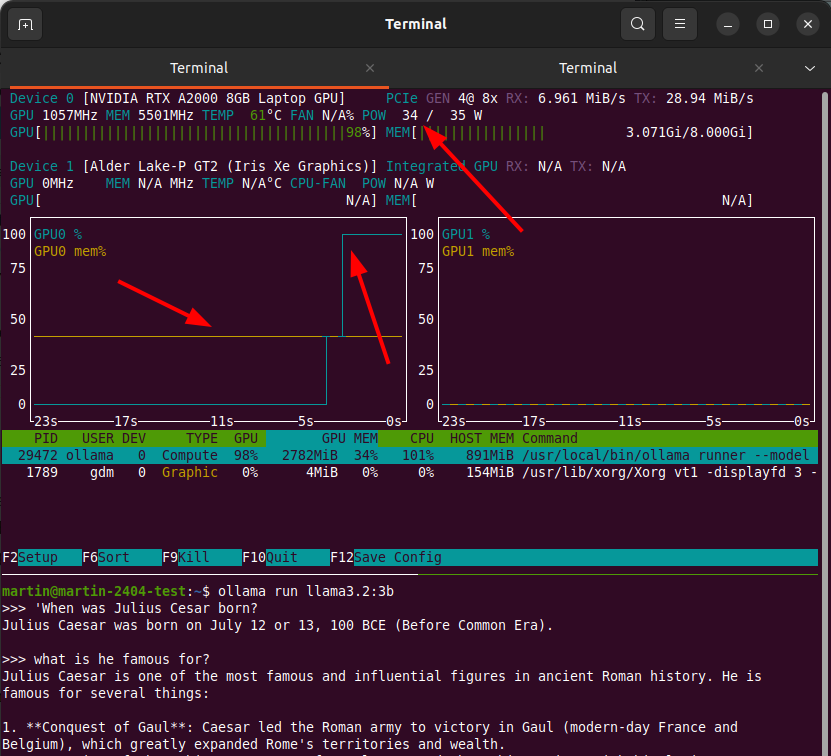
Finally, finally, some hands on stuff with AI in a blog post. After discussing some theory in part 1 and part 2 of this series, the first thing I wanted to explore was how I can run Large Language Models (LLMs) locally instead of using them in the cloud. After looking around a bit I saw two potential options for me: Ollma and LM Studio. As I wanted to have a solution I could run on a server without a GUI, I decided to go for Ollma, as it is an open source and MIT licensed command line solution to download and run LLMs. LM Studio is probably a good choice, too, but it is centered around a graphical user interface, which is not what I wanted to have for my initial ‘raw’ experiments.
Continue reading My AI Learning Journey – Part 3 – LLMs at HomeMy AI Learning Journey – Part 2 – How Do LLMs Work?
Before going to the practical aspects of my AI learning journey, I set out to understand how Large Language Models (LLMs) work, what the future potential of the technology might be and what kind of dangers might await us if things are running away. There is a lot of material out there on all of these topics and the first thing I wanted to find was an explanation of how LLMs work in less than 10 minutes.
The 10 Minute Intro
Here’s a good video on the topic by Matt Penny on Youtube. He has lots of videos on AI topis that have more than 10k views and a subscriber base of 17k at the time of writing. One of his videos has even been viewed more than 200k times. And yet, this particular video on the basics, posted 9 months ago, has less than 500 views. 200k vs. 500 views, I think that says a lot where the interest of 99.99% of the population lies. Anyway, if you want to understand the basics, including what a ‘token’ is, a word that is used all the time when talking about LLMs, how they work and how much a question costs that is being run through them, then this is your place to go.
Long story short, i.e. my personal elevator pitch: All LLMs we use today generate output text based on input text. They do so based on a previous massive learning phase, in which an LLM has learnt which words follow after each other in a large text corpus. Large in this context means the better part of text that can be found on the Internet today. An LLM doesn’t understand the output that it makes, it doesn’t reason, it doesn’t think, it applies the previously learnt knowledge which words follow which from a statistical point of view.
Continue reading My AI Learning Journey – Part 2 – How Do LLMs Work?My AI Learning Journey – Part 1 – Setting Sail
So far I’ve mostly used AI systems in search and a little bit for AI-assisted coding in a very basic form. But the world keeps screaming AI and I have seen a number of interesting use cases recently that might be useful to me that have sparked further interest. As the questions and potential use cases kept piling up, I decided to gather them and to make a learning journey out of the exercise. Reflecting and documenting is part of this process, so I decided that a good way to do this is to start ‘a little series’ on this blog. This way, I can remember what I did and learnt later, and at the same time I might give you some ideas and practical tips should you be interested in the topic. That being said, here’s the list of topics I would like to address over the next few weeks:
Basic Questions
How do LLMs work on the inside? I’m looking for a short and high level technical primer, as I would like to understand the basics, being well aware that the maths behind it is not really my cup of tea. But that’s OK, we live in a highly specialized world, and it’s important to understand the basic principles to be able to build on them. I think I do have a good understanding of the basic concepts of the layers between the silicon far down below and high level programming languages like Python and modern server systems. From that point of view, AI and LLMs are yet another layer on top. This learning journey should help me to understand how that latest layer on top works, what its limitations and future potentials are, and how I can benefit from it.
Running LLMs Locally
Having stuff run in the cloud outside my control creates two problems for me: First, I have no idea how much hardware and energy is really required to run LLMs. And secondly, I really don’t want my personal data flowing out to all sorts of data centers belonging to all sorts of big tech companies. But it’s possible to run LLMs locally and I want to find out what is required for this and how large or small these local LLMs are compared to what runs in the cloud today that drives ChatGPT, Perplexity and many other systems. Open source technologies like Ollama and Open WebUI are two software projects among many that might help me here. Fortunately, I do have a bit of CPU and GPU power at home and I will put that to good use for this learning journey.
Renting GPU Power
A middle ground between LLMs on premise on the one hand and ‘paying per token’ for LLMs running in big data centers are virtual machines or docker containers one can rent with GPUs attached, on which LLMs can be run (somewhat) privately as well. So would that work for me and what is the cost involved?
LLMs in Open Source Software
I’ve noticed that my self-hosted office suite based on Nextcloud and OnlyOffice can also tie in AI and LLMs for things such as search, translation, help with grammar, letter writing, etc. etc. The obvious questions are: Can I run that with the hardware that I have at home, would it be useful for me, and how does this compare to what is available in proprietary and centralized systems?
AI Assisted Coding
As mentioned at the top of this post, I’m very much interested in AI-Assisted coding, which is different from Vibe Coding. I’ll explain later. Anyway, I have done some fairly basic stuff with this in the past but I’ve noticed that it has now become possible to interact with AI systems in a way that code is generated and changed on the fly based on a conversation with an AI system in the code editor itself. That sounds exciting and I want to try different options if the software that runs on my end remains open source without telemetry. Let’s see if that is possible.
Trying Out Different Systems
I have few illusions that whatever I can run with relatively inexpensive hardware at home is no match for the LLMs and systems of big corp. And for some things like AI assisted programming, using remote LLMs might even work for me, as most of my code ends up as open source on a public git repository anyway. No privacy and secrecy involved here. To see what is possible and useful to me, I’d like to experiment with different systems to solve practical problems I have on my to-do list.
Getting to Grips with 3GPP Specs
Once upon a time, one could read 3GPP specs, understand them and at the same time get an idea of how networks out there really work. That probably ended after 3GPP Release 8. Some would say it was even earlier. The last 10 iterations of the specs of the last two decades have added a lot of stuff that is interesting at best and confusing at worst, but not used anywhere in real networks. These days, you don’t see the forest for the trees anymore in those documents. So could an LLM help me to reduce the pain and let me understand more quickly how some mechanisms that are actually used in real networks are specified across different 3GPP specification documents? So far I haven’t seen anything, but perhaps I haven’t looked hard enough? Let’s see.
Let’s Go!
So long story short, this is not going to be a single weekend project. But it doesn’t have to be, because there are so many interesting questions and possibilities around those topics in my head, so this promises to be an interesting ride.
What Does TOTP Protect From?
This post is a follow-up on the previous post about how I can use open source software for Time-based One Time Passwords (TOTP), also referred to as OTP in many cases. As shown in the previous post, TOTPs are generated from a common secret that is stored on the client and the server. And that is it’s weak point! If credentials are stolen on the server side, the common secret goes with it. If the attacker is then able to decrypt the hopefully ‘salted‘ password, the common TOTP secret is readily available and the game is lost. So what is TOTP good for then?
Continue reading What Does TOTP Protect From?TOTP Authentication – Open Source and Between Devices

These days I am using a number of services on a regular basis that require a 2nd factor authentication in addition to a password. Two of them send me a 6 digit time-based one time password (TOTP) over SMS each time I want to log-in. The other two send the 6 digit code by email. While that works quite well in general, there are two problems with this: First, SMS is sometimes a bit laggy and said not to be secure enough. And second, using email as a second factor for authentication makes me dependent on a particular provider if I don’t own the domain name. Not ideal. So when I recently had a closer look at the TOTP mechanism, I noticed that it is a standardized procedure and there are open source authenticator apps available that work with pretty much all services that offer TOTP passwords with an authenticator.
This is a game changer for me, as I was shying away from TOTP apps so far, as I didn’t want to install a multitude of authentication apps. Also, a proprietary app that syncs key material with a hyperscaler was obviously out of the question as well. Having an open source implementation that is totally local and under my control, however, changes the story. And even better, I already had an app installed on my Android device that could do the job for all websites I’m using: KeePassDX.
Continue reading TOTP Authentication – Open Source and Between DevicesUbuntu 24.04 – Wayland Remote Desktop Sharing Over Slow Lines
This is a follow up to my longer previous post where I had a detailed look at how well remote screen sharing works in Ubuntu 24.04 for Wayland desktop sessions. Everything works pretty smooth while connection speeds are high and delay is low. But how does it look like when connectivity is slow? This is an important question for me that needed an answer, because quite often, I do support people behind a slow cellular uplink because they are in a ‘deep indoor scenario’ and no other connectivity is available. So here we go:
Continue reading Ubuntu 24.04 – Wayland Remote Desktop Sharing Over Slow LinesWayland, Remote Desktop Sharing and Ubuntu 24.04 – Better Than on 22.04?
Wow, 4 years ago, I had a first look at Remote Desktop Sharing of a Wayland desktop of Ubuntu 22.04. At the time it was apparent that Wayland would replace X-windows in the medium term and I needed a solution for remote help when X-windows was no longer an option. At the time, I found it working overall, but the main two drawbacks was a strange delay of the last typed two characters and the inability to access a locked screen. As the next Ubuntu LTS version (26.04) is about to be released just about a month down the road, I thought I’d have another go at it and have a look at how Wayland remote desktop sharing works on the current LTS version, 24.04.
Continue reading Wayland, Remote Desktop Sharing and Ubuntu 24.04 – Better Than on 22.04?Network Printing with Linux – IPP, Raster, JPEG and PDF
Hm, perhaps a bit of a boring headline, but as my new printer worked out of the box without any configuration required, I was wondering how this could work, as Ubuntu 22.04 I currently use is older than the printer model.
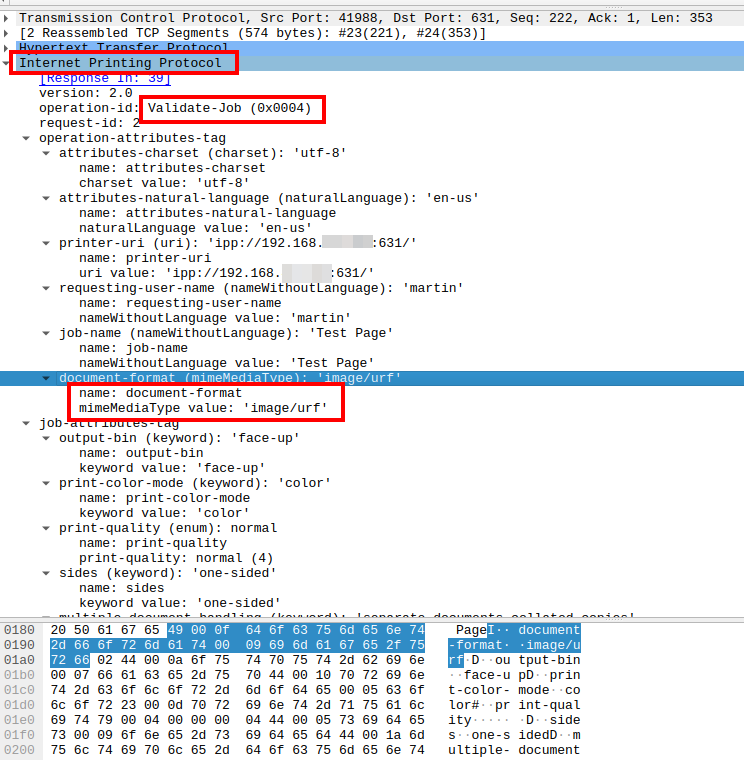
As my printer replacement cycle exceeds a decade, I was not quite up to date on this topic anymore and after digging into the topic, it seems that there are two main reasons it was working out of the box on Linux: Apple picked up and evolved the CUPS printing specs used by Linux already for some time, and all operating systems, including Android/iOS started using the Internet Printing Protocol (IPP) as a standardized way to talk to printers. The result: No manufacturer drivers required anymore. OK fine, I thought, so how does it work?
Continue reading Network Printing with Linux – IPP, Raster, JPEG and PDFHP Smart Tank 7307 – Driverless Printing and Scanning with Linux
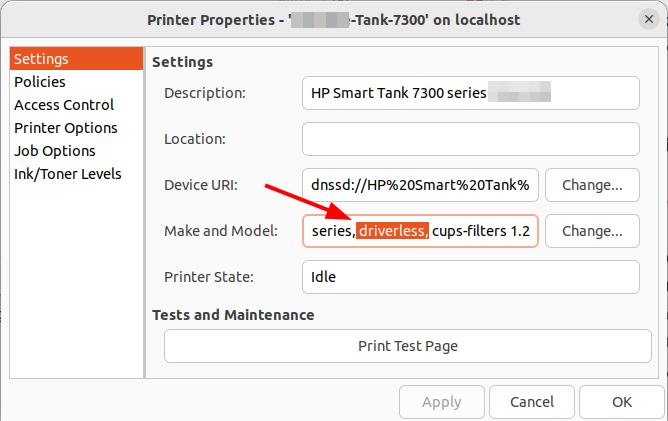
All right, after having had a look at the printing costs of my new HP Smart Tank 7307 ink printer / scanner combination in the previous post, here’s a follow up on how easy it is to get printing and scanning working with a Linux notebook in 2026. And to make things a bit more difficult: I’m a bit behind the times as I still use Ubuntu 22.04 LTS from back in 2022, so it’s unlikely to have the latest software and drivers. So I worried a bit that getting a printer to work that was most likely released after this date would be a bit of a hassle.
Continue reading HP Smart Tank 7307 – Driverless Printing and Scanning with Linux